NARRATOR: Luminaries. Talking to the brightest minds in tech.
MICHAEL DELL: And my hope is that we come together to share more of the technology, and expertise, and products, but that we share a vision of a future that is better than today. A vision of technology as the driver of human progress.
[MUSIC PLAYING]
NARRATOR: Your hosts are Mark Schaefer and Douglas Karr.
MARK SCHAEFER: Welcome everyone to another episode of Luminaries where we talk to the brightest minds in tech. This is Mark Schaefer with my co-host of two years now. We’ve been doing this two years, Doug. I’m so happy. Can you believe it?
DOUGLAS KARR: It’s been an incredible ride. And I feel we connect with all these brilliant people. And I feel like I’m not worthy.
MARK SCHAEFER: We really have talked to some amazing people. And today is no exception. I guess if you had to pick a theme for today’s show, it would be the I’s– have it.
[LAUGHING]
Thank you for laughing. Was that a good joke, or was that a lame joke?
DOUGLAS KARR: We’ll let our audience decide.
MARK SCHAEFER: OK. If it was a lame joke, would you tell me? Or are you, sort of, like the Ed McMahon of the luminaries where you would never disagree?
DOUGLAS KARR: I’m going with the Ed McMahon.
MARK SCHAEFER: Well, that’s all right. I like that. So listen, I want to welcome the founders of Voxeleron, Jonathan Oakley and Daniel Russakoff. They are the principal scientists behind this amazing company. And fellas, I’d love to welcome you to our program. We’re so honored to have you here.
And I’ve read through your material, and I’m blown away by what you’re achieving. But honestly I’m afraid that I’ll botch it up if I try to describe what you actually do. Can you help me out? Tell me a little bit about what Voxeleron is about.
DANIEL RUSSAKOFF: Sure. First off, thanks for having us on. It’s a real privilege to be here. And it’s my first ever podcast. This is Daniel here.
MARK SCHAEFER: Oh, that’s awesome! That’s great!
DANIEL RUSSAKOFF: So I think to understand what we do, it helps to take a step back. Jonathan and I both got our PhDs in the field of computer vision with specific applications in medical image analysis. We actually met at Fuji Film working in radiology. This is the first medical discipline to really embrace automated analysis. And there was a real appetite for it.
So we were kept very busy working with the state of the art technologies on real world interesting problems and with great results. We’re also helping bring those algorithms through the regulatory process. So it was a real education for both of us. Then, Jonathan left for Carl Zeiss Meditec and the opportunity to work on a new imaging modality called optical coherence tomography. And I’ll take it from there.
JONATHAN OAKLEY: Thank you for having us.
MARK SCHAEFER: Now is this your first podcast too Jonathan?
JONATHAN OAKLEY: Yes, it is my first podcast.
MARK SCHAEFER: Yay! Look at this! We’re breaking new ground everywhere today.
JONATHAN OAKLEY: Yeah. Social media is not our thing. We occasionally tweet.
MARK SCHAEFER: Well it is now. Here we go.
JONATHAN OAKLEY: Yes, these are new inroads, and we’re glad to travel them. So indeed, it was the case that having a background in radiology was extremely useful and extremely impactful at size. The focus had been on understanding noise and signal, which turned out to be pretty irrelevant to the image interpretation tasks that they needed to have diagnostic utility as they moved with this new modality and into 3D, which was, pretty much, unheard of in ophthalmology at that time is, kind of, 2 and 1/2 d solutions with a previous scanner and so on.
The strength was clearly the hardware. So it was great. It was exciting to work on this stuff. And one particular algorithm I worked on in a retinal segmentation it had utility and glaucoma, which is a complex neuropathy. So other neuropathy, neurological disorders also, wanted to use this measurement. And I was lucky enough to work with the multiple sclerosis lab at Johns Hopkins. And we published extensively on our findings there.
And this is extremely exciting. But I knew even then that if I joined forces again with Daniel we could do way better using new, more advanced algorithms. And that’s exactly what happened. The idea at that time was that we could create Voxeleron and do that in support of neuroophthalmic applications because this was really new, using the eye as a window to the brain.
I mean, we hear that all the time now. But when we formed Voxeleron almost nine years ago, this wasn’t the case. So we did exactly that. And we’re into these technologies. We’re into the clinical application, and then somewhat unburdened by larger corporate demands, we’ve been able to focus exactly on those things. Develop more and more algorithms.
But the focus has returned actually to ocular diseases. Just based on the fact that there’s larger, unmet needs in that area. For example, there’s no good [INAUDIBLE] and segmentation algorithm available in the instruments today. And that’s very important for dry AMD. AMD, a disorder that can lead to blindness that afflicts 10 million people in the United States. It’s the worldwide leading cause of vision loss for people over 50.
And so these are important measurements. These are important diagnostics. And people aren’t addressing them particularly well. And while we don’t make the scanners, we can work with all of the scanners. So to some extent, we like to think we’re kind of like a Photoshop for OCT analysis. We’ll work with anything, and we’ll do it with often more advanced tools, more clinical endpoints, and so on. So that was the etiology, if you will, of Voxeleron.
DOUGLAS KARR: You’re combining traditional computer vision with AI. Is the gap that you’re closing the interpretation of the results?
DANIEL RUSSAKOFF: So I like to think that what we’re doing– and to be fair, others are doing too– is sort of democratizing expertise. You know, the best physicians in the world right now are still only human and can see a finite number of patients in a given day. Essentially, we’re building their expertise into our systems using our technology to try to provide all physicians with world class diagnostic assistance.
So if we’re doing our jobs right, anyone anywhere with access to an OCT scanner and the internet can receive the kind of diagnostic care you’d get at, let’s say, the best university hospitals. But that brings up another important point because the pace of innovation in medicine is staggering at this point. The experts we’re trying to imitate.
They’re getting inundated with all kinds of data. Today, it’s high res 3D images. You know, tomorrow it’ll be entire genomes. There’s no way they can sift through all that information in any reasonable amount of time without serious automation. And I think this is another spot where we can have a huge impact. You know, our software helps physicians quickly explore these huge data sets and get the information they need to make the correct diagnosis.
MARK SCHAEFER: So first of all, I love what you’re saying here because Doug and I have had the opportunity to talk to many wonderful experts. Really, some of the greatest minds in the business. And often we’ll ask them, well, what technology application are you most excited about? And almost always, it has something to do with the medical field.
They just think that the way technology is being applied to the medical field is just going to be a game changer. And it sounds like that’s what we’re talking about here. So why the eye? What’s special about the eye. I’ve read how other companies, like Watson, they’re trying to get into the medical field so doctors can make diagnosis more quickly. So what’s tricky about the retina? What makes that more complex than other parts of the body?
JONATHAN OAKLEY: Well first off, I’m not a clinician. I’ll take on some of the question. It’s certainly complex. It’s essentially an extension to the brain. Some people say the retina is the front of the brain. So it’s made up of neuronal tissue. It has cell bodies. They have axons. They have dendrites.
These feed through the optic nerve, head, into the optic nerve. And there the axons are myelinated and go on to the mid brain and then to the visual cortex. So it’s a part of this whole central nervous system. But it is neuronal. So it truly is an extension to the brain. And it’s the visible part of the brain. So it’s very interesting.
If you have any neurodegenerative disorder that has a manifestation structurally in the eye, you can measure it. You can’t measure it readily. You don’t need an MRI scanner. You can use an office based OCT. And you can see what changes are occurring. And then, this can lead to the development of new therapeutics.
Also, the diagnosis of various things. It’s very complex. There’s other things going on. I mean, there’s pressure that can build up in the eye due to a lack of acquiesce outflow. You know, that’s a symptom of glaucoma. There can be surgery that can then reduce that. And your susceptibility can relate to how thick or thin your cornea is. So it is complex, but the diagnostics are really advanced.
The imaging is fundamental to this. The trick, I think, is the interpretation. This needs to be done in a timely way. A lot of these diseases can be asymptomatic. And we don’t know about them unless we happen to be scanned and it happens to be read by a top ophthalmologist. And these people are thin on the ground. And imaging is really the forte of AI or deep learning. And this is why it can play such an important roles, can be so impactful to modern clinical support, decision support, drug development, and so on.
And this can already be seen. A company called IDx has a deep learning based diabetic retinopathy screening tool. And it’s not decision support. It’s actually the decision. It’s FDA approved to make the referral. So this is significant. So yeah, imaging is super important in ophthalmology. The eye plays an important role in, of course, ocular diseases but neuropathy and, in general, systemic diseases that have manifestations in, both, the retina and choroid.
And because we can readily image it, this is why it’s so important today. And the interpretation though has to be done and, again, has to be done in a timely fashion, which is why deep learning and these advances in image interpretation is so critical.
MARK SCHAEFER: And I should have asked earlier, but this is available now, right? This is beyond development or beta. You’re rolling this out now. Is that right?
JONATHAN OAKLEY: That’s right. I mean, today, there’s multiple labs using the tool to appropriately manage MS patients. You’ve often read about the so-called retinal nerve fiber layer. This is the axons of the ganglion cell bodies. These are neuronal cells thinning with Alzheimer’s. But in ocular diseases, OCT, and OCT analysis, quantification is actually the mainstay of ophthalmic practices. It is the standard of care. So this is out there.
The full clinical utility is only scratched upon, I would say, in neurological diseases. Our understanding is in increasing all the time with these tools, with data, with shared studies. So largely, it’s out there in ocular diseases. Some university hospitals are using it day to day, routinely, and arguing that others should, and it should be also the mainstay in neurological diseases.
So we’re at quite an exciting area. I mean, I did my PhD. I graduated from my PhD in 2000. And we were ready to embark upon the so-called decade of the brain. We had all these fantastic 3D imaging, and all the algorithms were coming into play. And this is the area that I was working on. And that’s actually what motivated me to do a postdoc in neuro imaging because it’s just such an exciting area.
I think, to some extent, it’s similar now with the eye and has been the last five years. This clearly is an exciting and important area. And it’s just critical that this fundamental research is done. So the tools that we offer– I mean, Orion software is a clinical research tool. The main uses are clinical research organizations, universities, pharmaceutical companies.
That’s because they’re doing clinical research. The main utility of OCT though today and in practice is in ophthalmology. And that is where it’s the standard of care. You won’t go far without having an OCT scan done. At least, in the Western world.
DOUGLAS KARR: And when we’re talking about OCT scan, I’m going to go nerd tech on you just because I know there’s a lot of other nerds out there listening. You know, a given scan, are we talking about gigabytes of data and then analyzing those against millions of algorithms to come up with possible scenarios?
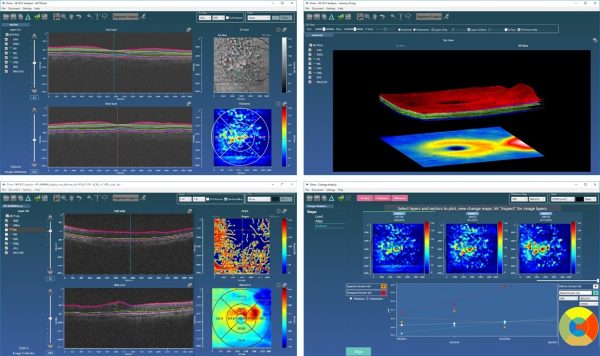
JONATHAN OAKLEY: So not gigabytes of data, no. Typically, about 100 megabytes would be a large OCT scan. It’s optical coherence tomography. So it is tomography, “tomo” the Greek for slice. So it’s a series of slices. So 2D images that are stepped through, in our case, the back of the eye, the retina.
Like you would have a tomogram from CT or MRI and so on. You have these image slices going through the subject of interest to give you a 3D volume. But they’re not that large. I mean, typically, you might have 128 or 200 slices stepping through maybe six millimeters in the eye. So you’d have a six by six millimeter over, say, two millimeters depth, which is plenty. So 2000 microns would be plenty to cover the extent of the retina.
So what’s interesting there though is the resolution is so small relative to, say, MRI and CT. So we have approaching cellular level imaging of neuronal tissue, and that’s really exciting. But this has been around for a while. [INAUDIBLE] now that we have adaptive optics to get you to actually see rods and cones in the back of the eye, see the actual photo receptors that you have.
So with adaptive optics, you can get even higher resolutions. In general, we approach the cellular resolution of around– well cellular resolution I like to think of of 10 microns. It approaches 30, 20 microns. And in terms of depth resolution, approximately, five microns.
MARK SCHAEFER: So this idea of shooting this light to this laser into tissue, and then interpreting the results, I mean, it sounds like there could be other applications for this. Do you see Voxeleron moving into some other things or other applications? Or really, in the foreseeable future, is it really about the retina and the eye?
DANIEL RUSSAKOFF: Right now, it’s about the retina and the eye. In general, in terms of deep learning, and artificial neural networks, or convolutional neuro networks, I think most of the work right now is being done in the field is on replicating human performance. So some examples of this are image net, natural language recognition, self-driving cars. You know, it’s the same in medicine. Most people, including us, are working towards teaching a computer to be as good as a human or as good as the best physician.
In terms of what’s next, I mean, some of the projects we’re working on now are algorithms that can do things that humans can’t. So for example, we’ve been working on prediction of AMD progression. Jonathan mentioned AMD earlier or Age Related Macular Degeneration. It affects more than 10 million people in the US. And I’ll just reiterate what he said.
It’s responsible for about 10% of blindness worldwide. It starts out it has a more or less benign, early, or what’s known as dry phase. And then, eventually, converts or progresses into a more dangerous late or wet phase. And it’s only in this wet phase where the vision loss occurs. And right now, physicians have no way of predicting when patients will progress from dry to wet.
We started working on this problem. And we actually try to get some experts together to give a guess. This is, sort of, a straw man for our work. And they refused to. I mean, not even for the research paper. There was just no basis for making the prediction. So we trained a neural net on this problem just using the outcome data with no human interpretation involved. And we got a very strong predictive score.
You know, we had a journal paper published on this just recently. And the neural net seemed to be able to pick out features from the data that humans just couldn’t see. And that’s something we’re very excited about.
DOUGLAS KARR: I’m curious. You know, a lot in AI is, basically, building models. And then, testing against data that already exists or deploying against unseen data. How are you evaluating the effectiveness of your learned model? So much of this depends on how you organize data and how you organize your experiments.
JONATHAN OAKLEY: It’s an important point but frequently missed, I feel, is how you test, and how you train, and how you split those. I mean, in general, we can say that if your performance in your classification task, your regression problem, if it’s lacking, it’s typically a bias or a variance problem, which means if it’s a bias problem you’re under-fitting, your model isn’t complex enough for the data.
It’s the variance problem. You’re over-fitting. You’ve got a very complex model. And the way we gauge whether we’re under-fitting or over-fitting is the classic split the data into a training set and a test set. Or often known as the cross validations set. So what we then do, we train, and then we test against the unseen data, and see how we’re doing. So this gives us an idea then of how other performance will be when we actually hit the road when we go into real world performance. How we’re doing on unseen data.
But one has to be careful. And this is one of the first things when reading results is how is that split done. If you’re looking at subject eyes, for example, and you’re training on a set of subject eyes, and then you test against to see how you’re doing in classifying, or diagnosing, or making an a measurement on another set of eyes, are you sure that the subjects’ left and right eye don’t spread across test and train data sets because there’s symmetry in someone’s eyes that can essentially mean you’re training on one thing and testing on something that’s actually very similar.
DOUGLAS KARR: Wow.
JONATHAN OAKLEY: And so you have no real way of knowing if you’re under-fitting or over-fitting. I mean, there’s just very standard techniques for doing this. Anecdotally, I worked at a company doing inspection of semiconductor machines. And one of the things we used to do is classify defects on a wafer. And we’d have to do these demos where we would show our classification performance.
And you’ve got thousands of defects on a wafer. Maybe hundreds. But you certainly have a lot. We used to put together leave one out classification, which is the most favorable for your approach. You would take all of the data, and you’d just leave one out. And then, you train on all of that data. And then, see how you do on that one that was left out. And you’d probably do pretty well because the likelihood is something very similar is already in your training set because it might be from the same wafer. It might be even from the same dye.
So it kind of drove then a meaningless result. So I always check, well, how have they split their data? A harder problem I worked on at another company was in fingerprint recognition where we had to recognize whether the fingerprint was real or not, was from a real hand. So from a real finger.
So was it a spoof, or was it actually a finger? And the point here being that you’ve probably seen the Bourne Identity and so on. And he tricks a fingerprint reader by taking a bit of sticky tape, and getting a fingerprint off the desk and spoofing the system. And people do it with gummy bears, and it’s often very embarrassing. So the problem with that and figuring out the real world performance of that system was difficult because, typically, we have a positive and negative example to do the supervised learning with.
Here, we had just the positive examples. Real fingers. But we didn’t know the parameter space of the negative examples because someone could come out with something completely different, or even take a finger out of– I don’t know– a mortuary or something grim like that. So you can’t cover the entire space. So there we had to be a little more careful. We had to use dimensionality reduction. This was before the deep learning days.
And kind of have a notion of a parameter space that could be occupied by actual, real fingerprints. So that was a little bit difficult. But I would say that common examples in deep learning and semantic segmentation of image data like we’ve worked on on nerve fibers. And so we’ve looked at the model that we’ve built. And if there’s similar performance, we might take one that has the smaller parameters set.
It was actually an interesting result in Daniel’s work on the AND prognostics that he managed to arrive at a simpler model, which is actually a very good result. And people might look at that and say, well, that’s not a deep learning model. But you know, you don’t win points for complexity. We want to deploy this stuff. And in order to generalize better, a simpler solution is actually a better one.
But there’s other tricks. But in general, it’s how you organize your data. And then, how you are able to understand where you are in terms of bias and variance of the system.
MARK SCHAEFER: So I was reading on your site how the use of the Voxeleron technology is actually increasing collaboration with universities and medical centers. So how are you enabling that?
JONATHAN OAKLEY: So I think we’ve been quite lucky with our collaborators. I mean, I was lucky to work with [INAUDIBLE] at Zeiss actually. And I’ve just been fortunate enough to maintain relationships with those people. I developed multiple algorithms with them at the time. So we stayed in touch. And if they’re still doing clinical research, then we work with them.
So I think the fortunate thing is we just managed to get a set of people who are just interested in getting things done. So there, we can count Johns Hopkins, IDIBAPS in Barcelona, Stanford University. We’ve been fortunate working with Moorefield’s University College London. Bascom Palmer, which is part of the University of Miami.
So we’ve had relationships that were really useful as we started out. We started out with no data. We needed a lab to give us data to work on to develop algorithms with a common interest. You know, we need this measurement. Could you help us? And that’s how that’s grown. And then, as we’re beginning to get more and more recognition, we want to see a turn up at conferences. We submit papers and so on. That’s just expanded.
And I would just summarize that we’ve been lucky. We worked with really good people who’ve been really beneficial to our development and helpful clinically. I think we’ve got pretty good domain knowledge in the areas we work in. But they’re the experts. And they’ve given guidance on what they would like to see developed. And then, we worked on that. I guess in summary, we’re just very fortunate with the people we work with.
MARK SCHAEFER: Well that’s fantastic. Well I have to ask the question that’s on everyone’s minds. We know that you named the Dell workstation that you’re using, Homer. Now was this for the Greek poet or for Homer Simpson? Because Doug and I have a bet on this.
[LAUGHING]
JONATHAN OAKLEY: Who’s betting on what?
[LAUGHING]
All right. I want to– obviously, Homer Simpson.
MARK SCHAEFER: Ah!
DOUGLAS KARR: Fantastic!
[LAUGHING]
MARK SCHAEFER: All right. Doug won.
[LAUGHING]
JONATHAN OAKLEY: Nice work.
DOUGLAS KARR: Yeah.
DANIEL RUSSAKOFF: We’re not that academic.
[LAUGHING]
MARK SCHAEFER: Oh, well thank you so much to Jonathan and Daniel for joining us today. This has really been amazing. It’s just what an adventure that you’re on, and we’re just so grateful that you’re applying technology for such a worthy cause. I actually have a niece that’s struggling with MS right now. So I mean, this is a topic that’s very close to my heart.
So thank you for all your great work. This is Mark Schaefer And on behalf of Doug Karr, we thank you for listening to Luminaries. Join us next time, won’t you? And we will continue our conversations with the brightest minds in tech.
[MUSIC PLAYING]
NARRATOR: Luminaries. Talking to the brightest minds in tech. A podcast series from Dell Technologies.
[MUSIC PLAYING]


 Mark Schaefer
Author, Consultant, College Educator. Mark is a leading authority on marketing strategy, consultant, blogger, podcaster, and the author of six best-selling books, including "KNOWN." He has two advanced degrees and studied under Peter Drucker in graduate school. Some of his clients include Microsoft, GE, Johnson & Johnson and the US Air Force
Mark Schaefer
Author, Consultant, College Educator. Mark is a leading authority on marketing strategy, consultant, blogger, podcaster, and the author of six best-selling books, including "KNOWN." He has two advanced degrees and studied under Peter Drucker in graduate school. Some of his clients include Microsoft, GE, Johnson & Johnson and the US Air Force
 Douglas Karr
Technologist, Author, Speaker. Pre-Internet, Douglas started his career as a Naval electrician before going to work for the newspaper industry. His ability to translate business needs into technology during the advent of the Internet paved the way for his digital career. Douglas owns an Indianapolis agency, runs a MarTech publication, is a book author, and speaks internationally on digital marketing, technology, and media.
Douglas Karr
Technologist, Author, Speaker. Pre-Internet, Douglas started his career as a Naval electrician before going to work for the newspaper industry. His ability to translate business needs into technology during the advent of the Internet paved the way for his digital career. Douglas owns an Indianapolis agency, runs a MarTech publication, is a book author, and speaks internationally on digital marketing, technology, and media.