
Quelque chose cloche dans vos données. Une valeur semble s’écarter du droit chemin. Et cela peut être plus important que vous ne le pensez. Qu’est-ce qu’une anomalie ? Comment la détecter ? Et surtout, comment l’exploiter au mieux ?
Une surprise, une aberration, une exception, vous ne savez pas encore exactement de quoi il s’agit, mais ce qui est certain, c’est que vous faites face à un résultat qui n’est pas celui attendu ou un comportement qui n’est pas celui habituellement observé. Bref, vous avez détecté une anomalie. Réjouissez-vous, car cette anomalie peut s’avérer précieuse dans de nombreux domaines, comme la sécurité informatique (détection d’intrusions), la finance (détection de fraudes), la santé (reconnaissance d’image) ou encore l’internet des objets (détection de capteurs endommagés).
Qu’est-ce que l’anormalité ?
Tout d’abord, il existe plusieurs types d’anomalies : ponctuelles, contextuelles ou collectives. Il est important de savoir les différencier, pour savoir comment les trouver.
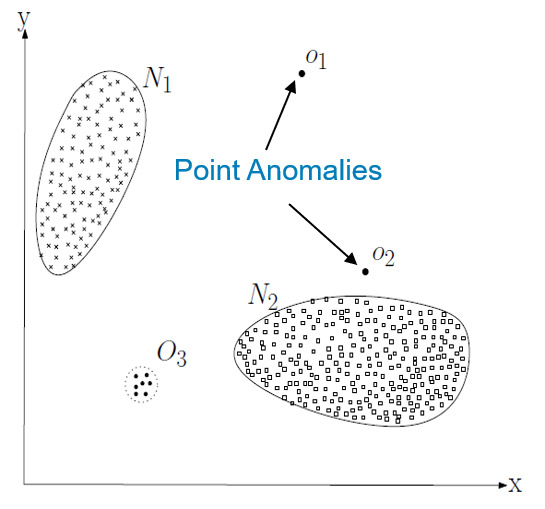
L’anomalie ponctuelle est la plus commune et celle qui est la plus recherchée. Il s’agit d’une mesure qui est considérée comme anormale par rapport au reste des données. Elle peut être schématisée comme un point isolé de la zone identifiée comme normale. L’exemple typique est un paiement important. La somme sera considérée par la banque comme anormale en comparaison des paiements habituellement effectués par le client. Les anomalies pourront donc avoir différentes valeurs en fonction des clients.
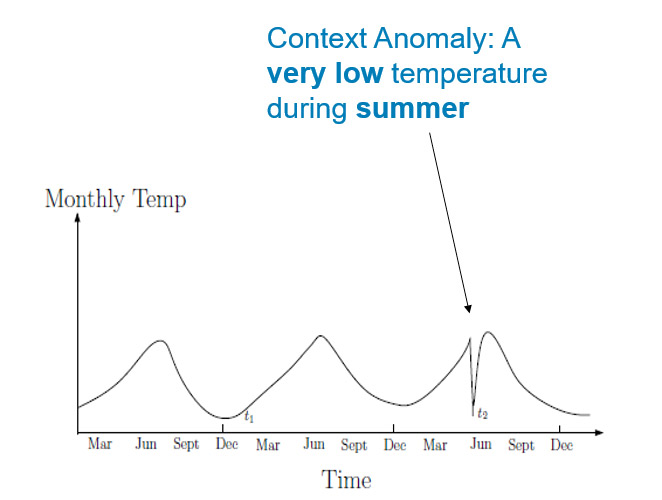
L’anomalie contextuelle est, comme son nom l’indique, une valeur qui peut être considérée anormale dans un contexte spécifique, mais normal dans un autre. Elle peut être représentée dans un schéma à deux dimensions ou la première indique la valeur recherchée et l’autre le contexte. L’exemple ci-dessous montre un relevé de température. Les valeurs t1 et t2 sont identiques, mais t2 devient une anomalie une fois replacée dans son contexte : l’été.
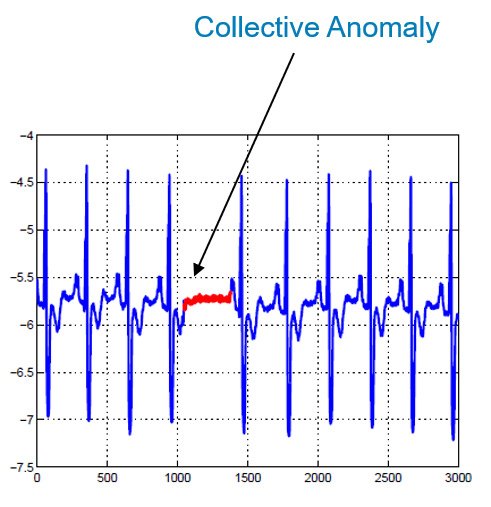
La troisième grande famille d’anomalies est l’anomalie collective. Cela signifie que la valeur n’est pas nécessairement anormale individuellement, mais qu’une répétition de cette même valeur peut l’être collectivement. L’exemple classique est l’électrocardiogramme. L’absence brève d’activité entre deux pulsations du cœur est normale. Si cette valeur se répète sur une plus longue période en revanche, c’est une anomalie.
Comme nous venons de le voir, savoir détecter ces trois types d’anomalies conduit à des applications très concrètes dans des secteurs très variés. Reste à savoir comment procéder.
Qu’est-ce que la normalité ?
Pour identifier l’anormal, encore faut-il avoir défini le normal. Les algorithmes d’intelligence artificielle vont s’avérer ici de précieux alliés, en décelant dans de grands ensembles de données les séquences qui se répètent. À partir de là, ils seront en mesure de comprendre le comportement habituel d’un processus ou l’état le plus courant d’un objet, mais surtout de détecter également tout ce qui s’en écarte. C’est ce qu’on appelle la détection non supervisée et c’est la situation la plus courante. Les données ne sont pas étiquetées au départ comme normales ou anormales. L’algorithme part du principe que, dans les vastes jeux de données qu’on lui fait ingérer, une majorité est normale, et va donc rechercher les instances différentes.
Il existe deux autres grandes catégories de détection. Avec la détection supervisée, les données sont étiquetées dès le départ comme normales ou anormales. L’algorithme va donc apprendre à catégoriser les nouvelles données par rapport au modèle qu’on lui a fourni. Ce scénario est plus simple mais assez rare, puisqu’il suppose de détenir en premier lieu des quantités suffisantes d’informations pour catégoriser chaque anomalie possible.
Enfin, la détection semi-supervisée est à mi-chemin entre les deux. On exploite dans ce cas des données étiquetées comme normales et des données non étiquetées. L’apprentissage est facilité puisque l’algorithme dispose d’une base de référence. C’est une technique utilisée pour les scenarios où l’on ne dispose que d’une très faible quantité de données anormales.
Des algorithmes et des processeurs
La mise en place d’un processus de détection d’anomalies va donc dépendre de l’information que l’on cherche à mettre à jour, de la qualité des données à disposition, mais aussi de l’infrastructure sur laquelle on l’exécute. Les équipes de la société californienne Voxeleron par exemple, utilisent une plateforme d’intelligence artificielle, basée sur les processeurs Intel Xeon SP Gold et les GPU NVIDIA Quadro GV100, pour travailler sur des images ophtalmiques en 3D. La rétine est un organe extrêmement complexe et les chercheurs étaient jusqu’à présent obligés de reconvertir les images en 2D pour être en mesure de les analyser. Grâce à la puissance de l’IA, ils sont désormais capables de détecter de manière très précoce les anomalies ponctuelles de la rétine chez les patients et d’améliorer considérablement le diagnostic des glaucomes et le suivi de l’évolution de la dégénérescence maculaire liée à l’âge (DMLA). Pour déceler l’anormal, l’IA devient la norme.
