«¿Qué es el edge computing?» Esta pregunta es cada vez más relevante. La explosión de puntos finales generadores de datos (IO) y de servicios de usuario ávidos de datos (entretenimiento de vídeo, servicios inteligentes de consumo, etc.) ha invertido la tendencia de la inteligencia centralizada y ha dado lugar a un cambio hacia la inteligencia distribuida. La transmisión de todos los datos a la nube pública o al centro de datos centralizado ya no es la norma. Alrededor del 10% de los datos generados por la empresa se crean y procesan fuera de un centro de datos centralizado tradicional o de una nube pública. Para 2025, Gartner predice que esta cifra alcanzará el 75%.
«Edge computing», una popular palabra de moda, es un término lleno de oportunidades de mercado y ambigüedad. Significa diferentes cosas para diferentes personas dependiendo del contexto de cada despliegue. Siguiendo este espacio en blanco desde 2017, he cristalizado la comprensión del «edge computing» en el mercado y en los contextos tecnológicos.
En pocas palabras, la informática avanzada es la informática (y el almacenamiento asociado, las redes) en el borde de la red, cerca o en los puntos finales. La Fundación Linux define la informática avanzada como «la entrega de capacidades informáticas a los extremos lógicos de una red con el fin de mejorar el rendimiento, los costes operativos y la fiabilidad de las aplicaciones y servicios». Gartner define la informática avanzada como «soluciones que facilitan el procesamiento de datos en / o cerca de la fuente de generación de datos».
Armado con el entendimiento anterior, lo mapearemos en el flujo de datos del mundo real siguiendo la topología de IT/red. La siguiente imagen es una representación de sistemas de alto nivel de la computación de borde:
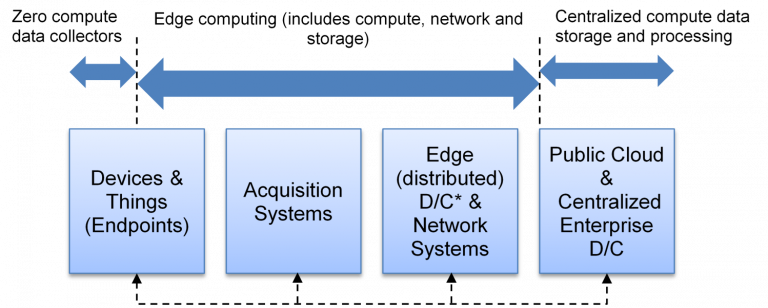
Empezaremos con los creadores de datos, que suelen ser puntos finales como sensores, dispositivos de telefonía móvil, etc. Estos forman el borde extremo de la red. Algunos endpoints tienen computación integrada, como los teléfonos móviles, mientras que otros sólo generan y transmiten datos. Los que tienen cálculo empiezan a formar cálculo de borde.
Los datos de los puntos finales tienen entonces la opción de fluir a través de las puertas de enlace cercanas, o de un enrutador/equipo Wi-Fi/W-LAN (SD-WAN), o de las torres de la torre de telecomunicaciones o de las torres de los techos. Estos forman sistemas de adquisición, que agregan datos y realizan funciones de condensación de datos. Por lo general, tienen cierto nivel de capacidad de procesamiento. Su tarea principal es recopilar los datos de varios puntos finales y enviarlos hacia arriba, o viceversa. En este paso, también suelen realizar algunos procesos de datos de bajo nivel, como el filtrado de datos (que determina qué datos se envían/bloquean) y el análisis de datos. Por lo tanto, la mayoría de los sistemas de adquisición se encuentran bajo el concepto de edge computing.
Los datos fluyen entonces de «sistemas de adquisición» a centros de datos y sistemas de red más cercanos. Estos pueden ser micro-datacenters en una fábrica, un CDN’s edge PoP (Punto de Presencia) o un centro de datos local o un centro de datos regional metropolitano para un proveedor de servicios de telecomunicaciones o de TI. Estos también incluyen centros de datos locales en contenedores para la empresa ROBO (Remote Office Branch Office). Estos centros de datos de borde realizan cálculos significativos, impulsando análisis en tiempo real y casi real. Los resultados de estos análisis son que se generan nuevos datos de salida. Estas salidas se envían de vuelta a los puntos finales para alguna acción/visión o se envían a la red a centros de datos centralizados o a la nube pública.
Los centros de datos centralizados o la nube pública pueden considerarse como almacenamiento centralizado y computación. Los datos se almacenan, y los análisis de grandes datos se pueden ejecutar con las grandes cantidades de datos almacenados.
Anteriormente, los datos pasaban de los «sistemas de adquisición» directamente a los centros de datos regionales, luego a los centralizados, o directamente a los centros de datos centralizados o a la nube pública a través de la conexión Internet/LAN. Como señalamos, el propósito era (y aún así, en algunos casos) almacenar los datos generados en una ubicación centralizada. Estos datos almacenados se utilizarían para realizar análisis. Lo que está cambiando ahora es la explosión de datos y el creciente deseo de impulsar el análisis casi en tiempo real. Esto llevó a costos prohibitivos de movimiento de datos y ancho de banda de red, dando lugar a nuevos e interesantes factores de forma en el centro de datos de borde. Es fascinante que la mayor parte de la implementación en el borde sea única para sus casos de uso en relación con el análisis, la entrega de contenido y la conectividad en todos los sectores, lo que puede causar confusión a quienes intentan comprender la computación en el borde. Cuando nos alejamos desde la perspectiva de la topología, la computación de borde es la computación disponible entre los puntos finales de computación cero y los centros de datos centralizados y la nube pública.
Vuelva el mes que viene para una inmersión más profunda en la taxonomía de la computación de borde. Descompondremos los centros de datos y los sistemas de red (distribuidos).
Mientras tanto, visite este blog para obtener más información sobre la computación en el borde y el ecosistema del borde.
1] Gartner, What Edge Computing Significa para los Líderes de Infraestructura y Operaciones
2] Fundación Linux, Glosario Abierto de Computación Edge
3] Gartner, What Edge Computing Significa para los Líderes de Infraestructura y Operaciones
