IT professionals generally acknowledge that infrastructure configuration changes are a major source (if not the major source) of unexpected IT service degradations and, worse, unplanned outages. Moreover, because the pace of business is so fast and meeting application service level objectives is so critical to business operations, even planned downtime (i.e., maintenance windows) to make infrastructure component and configuration changes are no longer tolerable.
IT organizations implementing well-conceived policies go a long way to control change management chaos. ISTM-oriented change management processes, change management systems, and staff (e.g., Change Managers and Change Advisory Boards) are commonplace. More recently, a whitepaper by Enterprise Management Associates identified an unexpected source of change management innovation through converged infrastructure systems and their purpose-built management software.
Let’s look at three common change management use cases:
- Incident Workarounds: In the heat of battle, when a service incident occurs, IT organizations following best practices have change management policies in place, giving Operations Engineers permission to immediately take prescribed actions (e.g., reboot a physical or virtual resource whose role and relationships are well-understood, divert network traffic elsewhere, invoke a command to move a workload, etc.) without having to ask permission. Take actions outside policy parameters, and you’re likely to put out one fire, only to start another somewhere else.
- Problem Resolution: Full root cause resolution may require pulling a faulty switch off the network fabric, a blade from a rack, or a disk from a storage array to replace them or to apply a patch or firmware to fix a component’s defect. Here’s where maintenance windows interrupt business, and data and workloads must quickly find a new temporary home during system change (i.e., component repair/replacement).
- Infrastructure Upgrades: There comes a time when every IT component must be upgraded (i.e., new firmware releases to upgrade hardware and new software releases to upgrade operating systems and hypervisors). Upgrades are among the biggest sources of planned downtime (i.e., taking days to weeks to apply new releases) as well as unplanned downtime (i.e., outages often resulting from the deployment of unauthorized, incompatible releases).
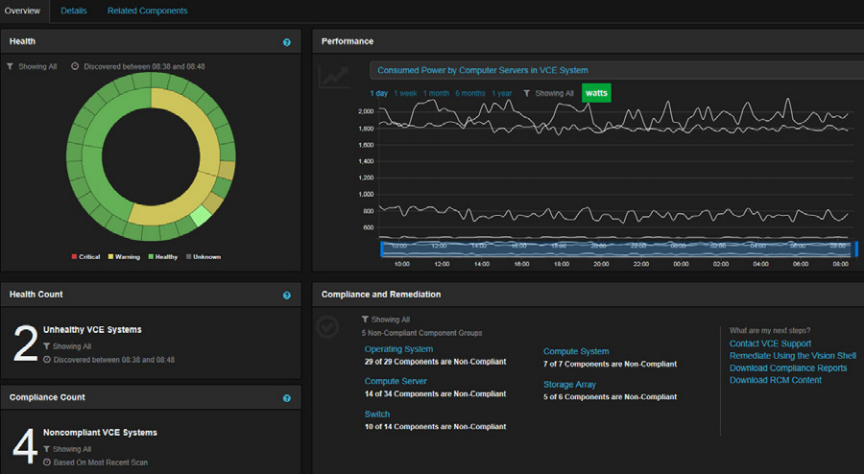
VCE converged infrastructure systems and management software combine several unique capabilities whose benefits, among others, include mitigating the chaos and unintended consequences of infrastructure change.
First, let’s define the capabilities:
- Architecture-Aware Monitoring: Displays all compute, storage and network components, their relationship, dependencies, and health
- Workload Fingerprinting: Correlates all virtual machines, their underlying compute and storage resources
- Converged Key Performance Indicator Monitoring: Displays compute, storage and network components across multiple systems as pools of resources
- Automated Firmware/Software Compliance Audits: Validates release levels on your systems, what needs to be upgraded, and if release levels have drifted out of compliance
- Automated Security and Technical Alert Audits: Validates if your technology components have security vulnerabilities and technical defects addressable by patches and upgrades
- Firmware/Software Release Pre-positioning: Downloads multi-vendor, multi-technology firmware/software releases and patches that are fully pretested and certified for compatibility
These converged infrastructure system and management software capabilities work in unison to address the three common change management use cases:
- Incident Workarounds: Policies for permissible workaround actions to prevent unintended consequences can be defined with greater accuracy and assurance because all parent-child infrastructure component as well as infrastructure-application workload relationships are known
- Problem Resolution: Available capacity and health of resources across all systems is always known, so workloads and data can be pulled off components that need repair and quickly relocated in the optimal place to assure continuous operations at expected service levels and with little or no business interruption
- Infrastructure Upgrades: Maintenance windows for firmware/system software release upgrades are dramatically reduced, unauthorized upgrades are easily uncovered, release incompatibility-induced outages are eliminated and bugs/defects are fixed faster
To get an independent analyst’s perspective, including two real world deployment stories, download Enterprise Management Associates’ white paper: Transforming Data Centers with VCE Converged Infrastructure Systems and Management Software
For additional related white papers and streaming videos, go to: www.vce.com/vision