Everything we do generates events – click on a mobile ad, pay with a credit card, tweet, measure heart rate, accelerate on the gas pedal, etc. What if an organization can feed these events into predictive models as soon as the event happens to quickly and more accurately make decisions that generate more revenue, lower costs, minimize risk, and improve the quality of care? You would need deep and fast analytics provided by Big Data platforms such as Pivotal HD 2.0 announced yesterday.
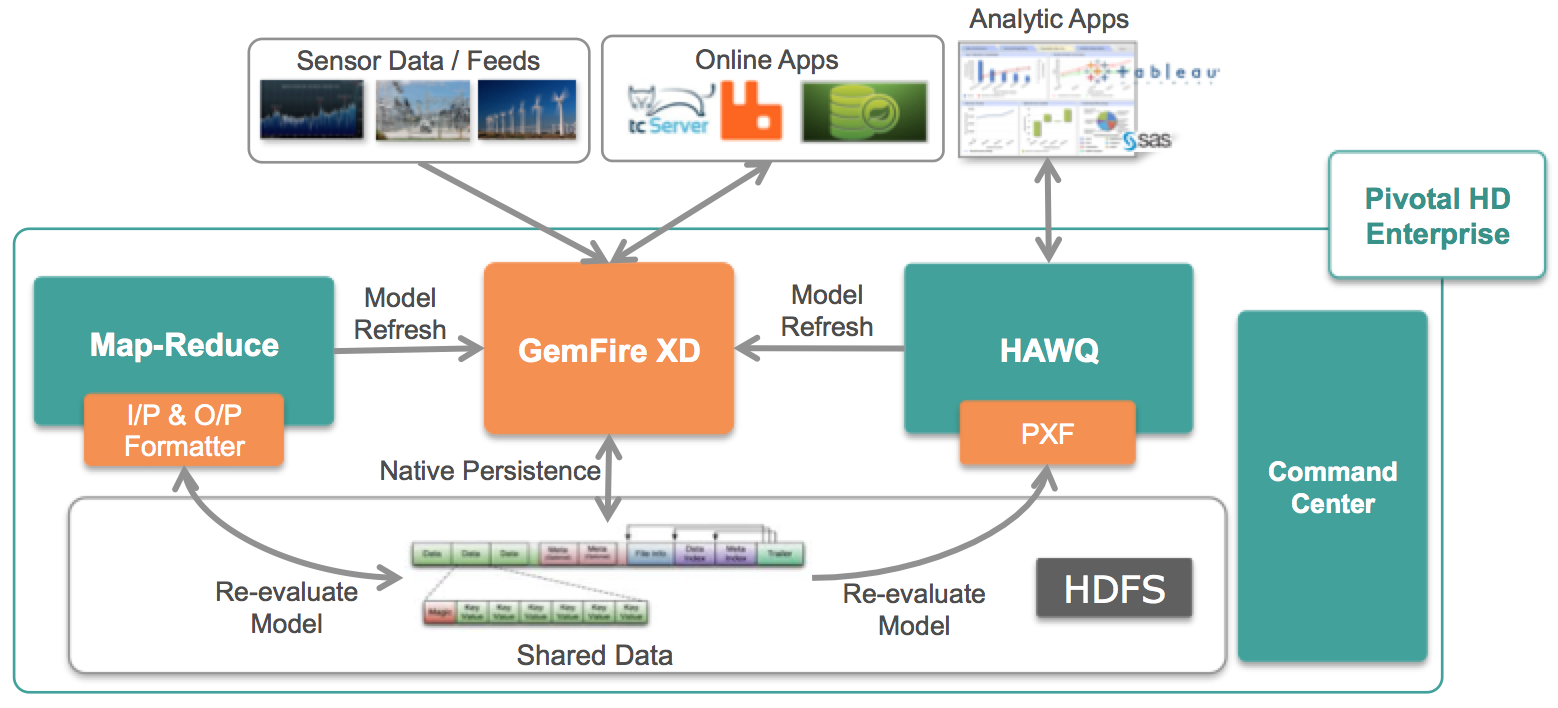
Pivotal HD 2.0 brings an in-memory, SQL database to Hadoop through seamless integration with Pivotal GemFire XD, enabling you to combine real-time data with historical data managed in HDFS. Closed loop analytics, operational BI, and high-speed data ingest are now possible in a single OLTP/OLAP platform without any ETL processing required. Use cases are ones that are time sensitive in nature. For example, telecom companies are at the forefront of applying real-time Big Data analytics to network traffic. The “store first, analyze second” method does not make sense for rapidly shifting traffic that requires immediate action when issues arise.
I spoke with Senior Director of Engineering at Pivotal Makarand Gokhale to explain the value in bringing OLTP to a traditional batch processing Hadoop.
1. Real-time solutions for Hadoop can mean many things- performing interactive queries, real-time event processing, and fast data ingest. How would you describe Pivotal HD’s real-time data services for Hadoop?
Real-time data services for Hadoop provides an in memory database tier for quick data processing, reasoning, or scoring – all before the data is persisted in Hadoop. A set of operational data can be maintained in-memory for quick response, querying and analysis. Real-time data driven businesses need to quickly derive insights from the most recent data. This is a critical need for organizations that want to capture, analyze, and take action on data that is being generated at high speeds from different sources.
2. The integration with GemFire XD allows data generated in real time to be written directly to HDFS, which can then be leveraged by HAWQ for SQL processing and analytics. What is the significance of a platform providing OLAP and OLTP with HDFS as the common data substrate?
One of the key things is that you no longer have a separate system for OLTP whereby you would have to perform some ETL before bringing it into the OLAP system. With Pivotal HD, the transactional data is immediately available for SQL analysis in-memory or in HDFS – no ETL required.
3. Hadoop is designed for batch processing or the loading of data in 64MB sequential blocks that are immutable. How does GemFire XD abide to this paradigm now that you are dealing with writing transactions to HDFS versus large, unstructured files?
GemFire XD has built enterprise class technology that allows GemFire XD to use HDFS as the long term storage of data. As inserts and updates are performed on the in-memory database table, GemFire XD writes the changes to a new file on HDFS and maintains metadata to keep track of the changes. This way GemFire can support insert/updates/deletes to database tables while still complying with the immutable nature of Hadoop file system.
Periodically, GemFire XD will perform clean up of the files in Hadoop to compact the data into a single new file to reduce HDFS footprint. Customers can also choose to leave all the historical files on HDFS to track transaction history and derive additional insight in the future if they desire to do so. The innovation lies in the efficiency of delivering the desired performance and scalability required for OLTP databases and real-time systems.
4. Can you provide a GemFire XD use case?
Instead of the batch processing of call records, telecommunication providers can process large volumes of call records in real-time (or integrate call records with other data streams like location data, tweets, etc.) to take immediate action on critical events such as adding capacity during an unexpected congestion or contacting a high value customer with a discount offer if a call is dropped.
5. Who are the ideal candidates for this platform?
Because GemFire XD is a SQL database, the ideal candidate is an organization looking at taking advantage of real-time data analytics over traditional batch SQL processing. Pivotal HD with GemFire XD would provide the primary, real-time data store and can co-exist with existing databases.
Other candidates are those that simply want to take advantage Big Data – large volumes of data being generated at high speeds, coming from different sources- and building new applications based on the insight derived from the analytic capabilities of Pivotal HD. Organizations that innovate through the repeating app-data-analysis cycle will have a competitive advantage. There are also organizations that have application bottlenecks and can use GemFire XD to overcome scalability and performance issue as well as explore opportunities with Big Data.
Lastly, organizations that perform real-time model scoring can now perform closed loop analytics whereby the model gets recalculated in real-time since now there is a single Big Data platform that combines OLTP and historical analytic capability.
6. HBase, Cassandra, and NoSQL are real-time Hadoop solutions. Is Pivotal HD an alternative or complementary solution?
Unlike HBase and Cassandra, GemFire XD is a high performance, in-memory SQL database with seamless integration to Hadoop to support real-time use cases such as transactional SQL, closed loop analytics, and operational BI. In addition to the advantages of SQL itself, GemFire XD’s feature rich querying capability, scalable distributed transactions support, and High availability for continuous operations and fast recovery make it ideal for building real-time applications. Our internal testing has shown that GemFire XD’s in-memory design for SQL data performs better than HBase and Cassandra for transactional applications manipulating SQL data.
You can also check out the comparison Wiki – GemFire vs. Cassandra vs. MongoDB
Read the Pivotal Blog on how Pivotal HD 2.0 also delivers a Business Data Lake architecture