Lately, I have spent large swaths of my time focused on Deep Learning and Neural Networks (either with customers or in our lab). One of the most common questions that I get is around underperforming model training with regard to “wall clock time.” This has more to do with focusing on only one aspect of their architecture, say GPUs. As such, I will spend a little time writing about the 3 fundamental tenets for a successful Deep Learning architecture. These fundamental tenants are: compute, file access, and bandwidth. Hopefully, this will resonate and help provide some thoughts for those customers on their journey.

Overview
Deep Learning (DL) is certainly all the rage. We are defining DL as a type of Machine Learning (ML) built on a deep hierarchy of layers, with each layer solving different pieces of a complex problem. These layers are interconnected into a “neural network.”
The use cases that I am presented with continue to grow exponentially with very compelling financial return on investments. Whether it is Convolutional Neural Networks (CNNs) for Computer Vision or Recurrent Neural Networks (RNNs) for Natural Language Processing (NLP) or Deep Belief Networks (DBN) for Restricted Boltzmann Machines (RBMs), Deep Learning has many architectural structures and acronyms. There is some great Neural Network information out there. Pic 1 is a good representation of the structural layers for Deep Learning on Neural Networks:

Orchestration
Orchestration tools like BlueData, Kubernetes, Mesosphere, or Spark Cluster Manager are the top of the layer cake of implementing Deep Learning with Neural Networks. These provide scheduler and possibility container capabilities to the stack. This layer is the most visible to the Operations team running the Deep Learning environment. There are certainly pros and cons to the different orchestration layers, but that is a topic for another blog.
Deep Learning Frameworks
Caffe2, CNTK, Pikachu, PyTorch, or Torch. One of these is a cartoon game character. The rest sound like they could be in a game, but they are some of the blossoming frameworks that support Deep Learning with Neural Networks. Each framework has their pros and cons with different training libraries and different neural networks structures (s) for different use cases. I regularly see a mix of frameworks within Deep Learning environments and the Framework chosen rarely changes the 3 tenets for architecture.
Architectural Tenets
I’ll use an illustrative use case to highlight the roles of the architectural tenets below. Since the Automotive industry has Advanced Driving (ADAS) and Financial Services have Trader Surveillance use cases, we will explore a CNN with Computer Vision. Assume a 16K resolution image that stores around 1 gigabyte (GB) in a file on storage and has 132.7 million pixels.
Compute
To dig right in, the first architectural tenet is Compute. The need for compute is one of those self-obvious elements of Deep Learning. Whether you use GPU, CPU, or a mix tends to result from which neural network structure (CNNs vs RNNs vs DBNs), use cases, or preferences. The internet is littered with benchmarks postulating CPUs vs GPUs for different structures and models. GPUs are the mainstay that I regularly see for Deep Learning on Neural Networks, but each organization has their own preferences based on past experiences, budget, data center space, and network layout. The overwhelming DL need for Compute is for lots of it.
If we examine our use case of the 16K image, the CNN will dictate how the image is addressed. The Convolutional Layer or the first layer of a CNN will parse out the pixels for analysis. 132.7M pixels will be fed to 132.7M different threads for processing. Each compute thread will create an activation map or feature map that helps to weight the remaining CNN layers. Since this volume of threads for a single job is rather large, the architecture discussion around concurrency versus recursion of the neural network certainly evolves from the compute available to train the models.
Embarrassingly Parallel
If we start with the use case, this paints a great story to start with for file access. We already discussed that a 16K resolution image will spawn 132.7 million threads. What we didn’t discuss is that these 132.7 million threads will attempt to read the same 1 GB file. Whether that is at the same time or over a time window depends on the amount of compute available for the model to train with. In a large enough compute cluster, those reads can be simultaneous. This scenario is referred to being “embarrassingly parallel” and there are great sources of information on it. Pic 2 denotes the difference between regular command and control on high performance computing workloads (HPC) with “near embarrassingly parallel” vs embarrassingly parallel in Deep Learning.
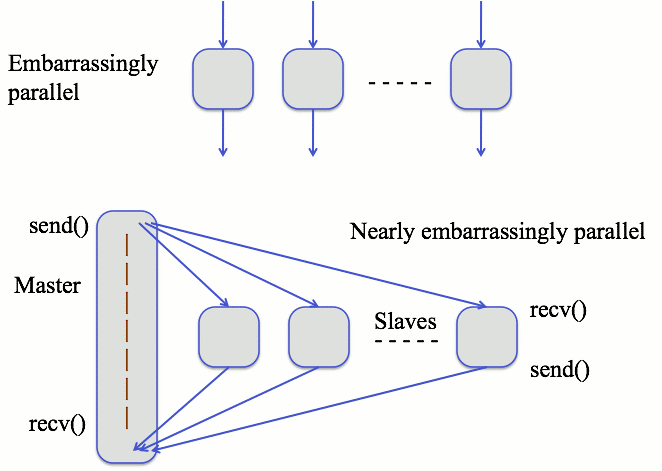
In most scale up storage technologies, embarrassingly parallel file requests lead to increased latency as more threads open the file. This eventually leads to a logarithmic asymptote that approaches infinity with enough file opens. This means that the more threads that open will often never complete until the concurrency level on the file open is reduced.
In true scale out technologies, embarrassingly parallel file opens are a mathematical function of bandwidth per storage chassis and number of opens requested per neural network structure.
Massive Bandwidth
I am often told that latency matters in storage. I agree for certain use cases. I do not agree with Deep Learning. Latency is a single stream function of a single process. When 132.7M files read the same file in an embarrassingly parallel fashion, it is all about the bandwidth. A lack of significant forethought into how the compute layer gets “fed” with data is the biggest mistake I see in most Deep Learning architectures. It accounts for most of the wall clock time delays that customers focus on.
While there is no right answer as to what constitutes “fast enough” for feeding the Deep Learning structures, there certainly is “good enough”. Good enough usually starts with a scale out storage architecture that allows a great mix of spindle to network feeds. 15GB per second for a 4 rack unit chassis with 60 drives is a good start.
Wrap Up
In summary, Deep Learning with Neural Networks is a blossoming option in the analytics arsenal. Its use cases are growing quite regularly with good results. The architecture should be approached holistically though instead of just focusing on one aspect of the equation. The production performance of the architecture will suffer depending on which tenet is skimped on. We regularly have conversations with customers around their architectures and welcome a more in-depth conversation around your journey. If you would like more details on how Dell EMC can help you with Deep Learning, feel free to email us at data_analytics@dell.com