This blog was co-authored by Jacci Cenci, Sr. Technical Marketing Engineer, NVIDIA
Over the last few years, Dell EMC and NVIDIA have established a strong partnership to help organizations accelerate their AI initiatives. For organizations that prefer to build their own solution, we offer Dell EMC’s ultra-dense PowerEdge C-series, with NVIDIA’s TESLA V100 Tensor Core GPUs, which allows scale-out AI solutions from four up to hundreds of GPUs per cluster. For customers looking to leverage a pre-validated hardware and software stack for their Deep Learning initiatives, we offer Dell EMC Ready Solutions for AI: Deep Learning with NVIDIA, which also feature Dell EMC Isilon All-Flash storage. Our partnership is built on the philosophy of offering flexibility and informed choice across a broad portfolio.
To give organizations even more flexibility in how they deploy AI with breakthrough performance for large-scale deep learning Dell EMC and NVIDIA have recently collaborated on a new reference architecture that combines the Dell EMC Isilon All-Flash scale-out NAS storage with NVIDIA DGX-1 servers for AI and deep learning (DL) workloads.
To validate the new reference architecture, we ran multiple industry-standard image classification benchmarks using 22 TB datasets to simulate real-world training and inference workloads. This testing was done on systems ranging from one DGX-1 server, all the way to nine DGX-1 servers (72 Tesla V100 GPUs) connected to eight Isilon F800 nodes.
This blog post summarizes the DL workflow, the training pipeline, the benchmark methodology, and finally the results of the benchmarks.
Key components of the reference architecture shown in figure 1 include:
- Dell EMC Isilon All-Flash scale-out NAS storage delivers the scale (up to 33 PB), performance (up to 540 GB/s), and concurrency (up to millions of connections) to eliminate the storage I/O bottleneck keeping the most data hungry compute layers fed to accelerate AI workloads at scale.
- NVIDIA DGX-1 servers which integrate up to eight NVIDIA Tesla V100 Tensor Core GPUs fully interconnected in a hybrid cube-mesh topology. Each DGX-1 server can deliver 1 petaFLOPS of AI performance, and is powered by the DGX software stack which includes NVIDIA-optimized versions of the most popular deep learning frameworks, for maximized training performance.

Figure 1: Reference Architecture
Deep Learning Workflow
As visualized in figure 2, DL usually consist of two distinct workflows, model development and inference.
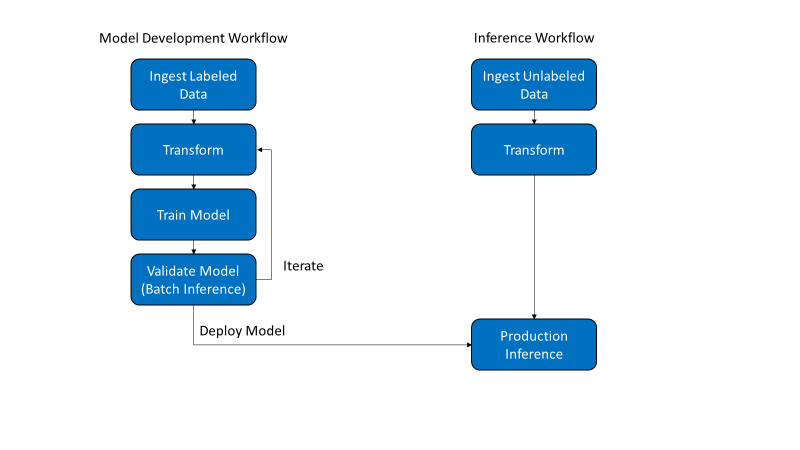
Figure 2: Common DL Workflows: Model development and inference
The workflow steps are defined and detailed below.
- Ingest Labeled Data – In this step, the labeled data (e.g. images and their labels which indicate whether the image contains a dog, cat, or horse.) are ingested into the Isilon storage system. Data can be ingested via NFS, SMB, and HDFS protocols.
- Transform – Transformation includes all operations that are applied to the labeled data before they are passed to the DL algorithm. It is sometimes referred to as preprocessing. For images, this often includes file parsing, JPEG decoding, cropping, resizing, rotation, and color adjustments. Transformations can be performed on the entire dataset ahead of time, storing the transformed data on Isilon storage. Many transformations can also be applied in a training pipeline, avoiding the need to store the intermediate data.
- Train Model – In this phase, the model parameters are learned from the labeled data stored on Isilon. This is done through a training pipeline shown in 3 consisting of the following:

Figure 3: Training pipeline
- Preprocessing – The preprocessing pipeline uses the DGX-1 server CPUs to read each image from Isilon storage, decode the JPEG, crop and scale the image, and finally transfer the image to the GPU. Multiple steps on multiple images are executed concurrently. JPEG decoding is generally the most CPU-intensive step and can become a bottleneck in certain cases.
- Forward and Backward Pass – Each image is sent through the model. In the case of image classification, there are several prebuilt structures of neural networks that have been proven to work well. To provide an example, Figure 3 below shows the high-level workflow of the Inception-v3 model which contains nearly 25 million parameters that must be learned. In this diagram, images enter from the left and the probability of each class comes out on the right. The forward pass evaluates the loss function (left to right) and the backward pass calculates the gradient (right to left). Each image contains 150,528 values (224*224*3) and the model performs hundreds of matrix calculations on millions of values. The NVIDIA Tesla GPU performs these matrix calculations quickly and efficiently.

Figure 4: Inception v3 model architecture
- Optimization – All GPUs across all nodes exchange and combine their gradients through the network using the All Reduce algorithm. The communication is accelerated using NCCL and NVLink, allowing the GPUs to communicate through the Ethernet network, bypassing the CPU and PCIe buses. Finally, the model parameters are updated using the gradient descent optimization algorithm.
- Repeat until the desired accuracy (or another metric) is achieved. This may take hours, days, or even weeks. If the dataset is too large to cache, it will generate a sustained storage load for this duration.
- Validate Model – Once the model training phase completes with a satisfactory accuracy, you’ll want to measure the accuracy of it on validation data stored on Isilon – data that the model training process has not seen. This is done by using the trained model to make inferences from the validation data and comparing the result with the label. This is often referred to as inference but keep in mind that this is a distinct step from production inference.
- Production Inference – The trained and validated model is then often deployed to a system that can perform real-time inference. It will accept as input a single image and output the predicted class (dog, cat, horse). Note that the Isilon storage and DGX-1 server architecture is not intended for and nor was it benchmarked for production inference.
Benchmark Methodology Summary
In order to measure the performance of the solution, various benchmarks from the TensorFlow Benchmarks repository were carefully executed. This suite of benchmarks performs training of an image classification convolutional neural network (CNN) on labeled images. Essentially, the system learns whether an image contains a cat, dog, car, train, etc.
The well-known ILSVRC2012 image dataset (often referred to as ImageNet) was used. This dataset contains 1,281,167 training images in 144.8 GB[1]. All images are grouped into 1000 categories or classes. This dataset is commonly used by deep learning researchers for benchmarking and comparison studies.
When running the benchmarks on the 148 GB dataset, it was found that the storage I/O throughput gradually decreased and became virtually zero after a few minutes. This indicated that the entire dataset was cached in the Linux buffer cache on each DGX-1 server. Of course, this is not surprising since each DGX-1 server has 512 GB of RAM and this workload did not significantly use RAM for other purposes. As real datasets are often significantly larger than this, we wanted to determine the performance with datasets that are not only larger than the DGX-1 server RAM, but larger than the 2 TB of coherent shared cache available across the 8-node Isilon cluster. To accomplish this, we simply made 150 exact copies of each image archive file, creating a 22.2 TB dataset.
Benchmark Results

Figure 5: Image classification training with original 113 KB images
There are a few conclusions that we can make from the benchmarks represented above.
- Image throughput and therefore storage throughput scale linearly from 8 to 72 GPUs.
- The maximum throughput that was pulled from Isilon occurred with ResNet50 and 72 GPUs. The total storage throughput was 5907 MB/sec.
- For all tests shown above, each GPU had 97% utilization or higher. This indicates that the GPU was the bottleneck.
- The maximum CPU utilization on the DGX-1 server was 46%. This occurred with ResNet50.
Large Image Training
The benchmarks in the previous section used the original JPEG images from the ImageNet dataset, with an average size of 115 KB. Today it is common to perform DL on larger images. For this section, a new set of image archive files are generated by resizing all images to three times their original height and width. Each image is encoded as a JPEG with a quality of 100 to further increase the number of bytes. Finally, we make 13 copies of each image archive file. This results in a new dataset that is 22.5 TB and has an average image size of 1.3 MB.
Because we are using larger images with the best JPEG quality, we want to match it with the most sophisticated model in the TensorFlow Benchmark suite, which is Inception-v4.
Note that regardless of the image height and width, all images must be cropped and/or scaled to be exactly 299 by 299 pixels to be used by Inception-v4. Thus, larger images place a larger load on the preprocessing pipeline (storage, network, CPU) but not on the GPU.
The benchmark results in Figure 5 were obtained with eight Isilon F800 nodes in the cluster.
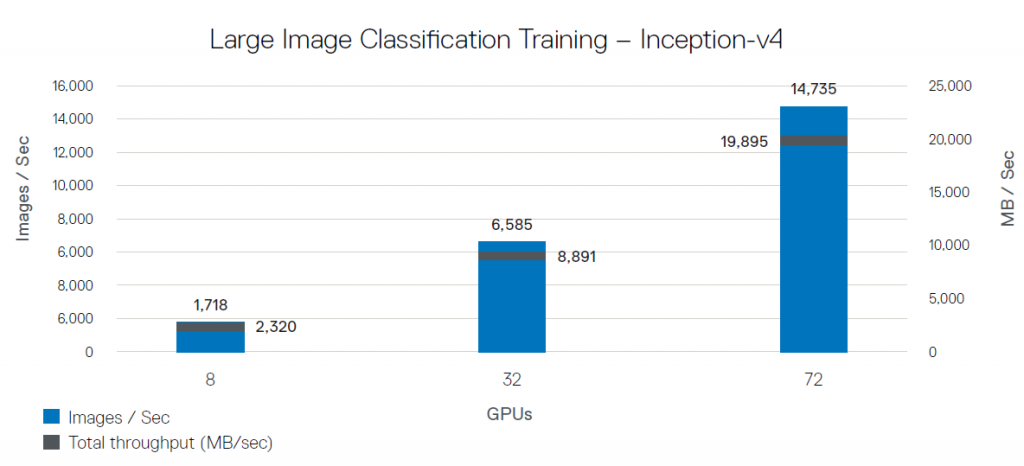
Figure 6: Image classification training with large 1.3 MB images
As before, we have linear scaling from 8 to 72 GPUs. The storage throughput with 72 GPUs was 19,895 MB/sec. GPU utilization was at 98% and CPU utilization was at 84%.
Conclusion
Here are some of the key findings from our testing of the Isilon and NVIDIA DGX-1 server reference architecture:
- Achieved compelling performance results across industry standard AI benchmarks from eight through 72 GPUs without degradation to throughput or performance.
- Linear scalability from 8-72 GPUs delivering up to 19.9 GB/s while keeping the GPUs pegged at >97% utilization.
- The Isilon F800 system can deliver up to 96% throughput of local memory, bringing it extremely close to the maximum theoretical performance limit an NVIDIA DGX-1 system can achieve.
Isilon-based DL solutions deliver the capacity, performance, and high concurrency to eliminate the IO storage bottlenecks for AI. This provides a rock-solid foundation for large scale, enterprise-grade DL solutions with a future proof scale-out architecture that meets your AI needs of today and scales for the future.
If you are interested in learning more about this, be sure to see the Dell EMC Isilon and NVIDIA DGX-1 servers for deep learning whitepaper. You’ll find the complete benchmark methodology as well as results for batch inference for model validation. It also contains the complete reference architecture including hardware and software configuration, networking, sizing guidance, performance measurement tools, and some useful scripts.
[1] All unit prefixes use the SI standard (base 10) where 1 GB is 1 billion bytes.
______________________________________________________________________________________________________________________________________________________
 About the co-author
About the co-author
Jacci Cenci
Technical Marketing Engineer, NVIDIA
Jacci has worked for the past two years at NVIDIA with partners and customers to support accelerated computing and deep learning requirements. Prior to NVIDIA, Jacci spent four years as a data center consultant focused on machine learning, big data analytics, technical computing, and enterprise solutions at Dell EMC.
